쿼리 실행 구조
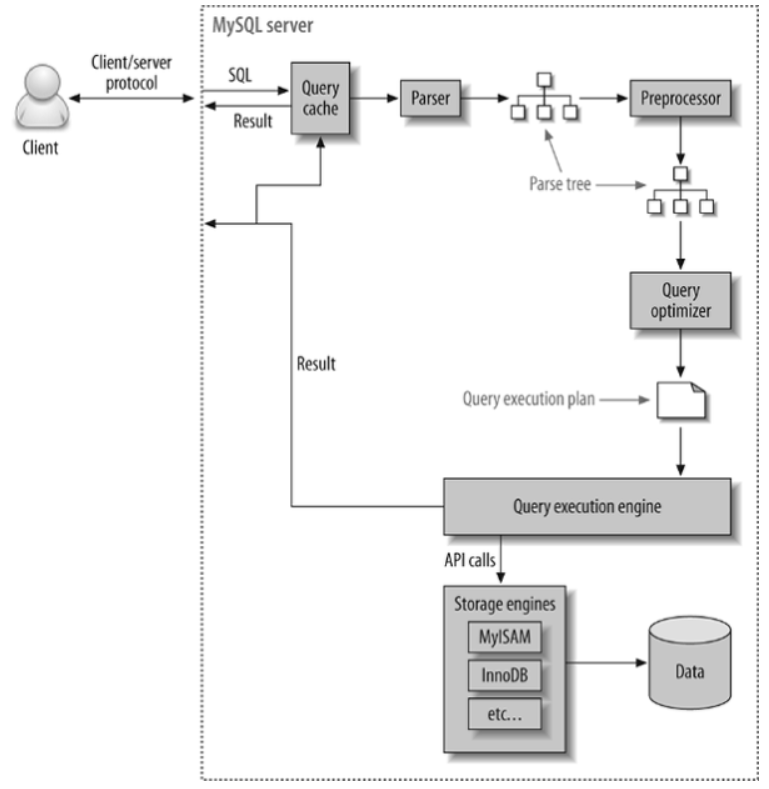
쿼리 실행 구조는 기능별로 다음과 같이 나눠질 수 있다.
1. 파서(Parser)
파서는 사용자 요청으로 들어온 쿼리 문장을 토큰(MySql이 인식할 수 있는 최소 단위의 어휘나 기호)으로 분리해 트리 형태의 구조로 만들어 내는 작업을 의미한다.
이 때, 만들어진 트리 형태를 파스트리(parse tree) 라고 한다.
쿼리 문장의 문법 오류는 이 과정에서 발견되어 사용자에게 오류 메시지를 전달한다.
2. 전처리기(PreProcessor)
파서 과정에서 만들어진 파서 트리를 기반으로 쿼리 문장에 구조적인 문제점이 있는지 확인한다.
각 토큰을 테이블 이름이나 컬럼 이름 또는 내장 함수와 같은 개체를 매핑해 해당 객체의 존재 여부와 객체의 접근 권한 등을 확인하는 과정을 이 단계에서 수행한다.
실제 존재하지 않거나 권한상 사용할 수 없는 개체의 토큰은 이 단계에서 걸러진다.
3. 옵티마이저(QueryOptimizer)
옵티마이저는 사용자의 요청으로 들어온 쿼리 문장을 저렴한 비용으로, 어떻게 가장 빠르게 처리할지 결정하는 역할을 한다.
자세하게 말하면, DBMS에서 쿼리를 최적으로 실행하기 위해 각 테이블의 데이터가 어떤 분포로 저장돼 있는지 통계를 참조하고, 그 기본 데이터를 비교해 최적의 실행계획을 수립하는 작업을 한다.
DBMS의 뇌의 역할을 한다고 볼 수 있다.
어떻게 하면 옵티마이저가 더 나은 선택을 할 수 있게 유도하는지에 대한 과정이 MySql 성능 최적화와 관계있다고 볼 수 있다.
4. 실행 엔진(Query Execution Engine)
옵티마이저가 두뇌라면 실행 엔진과 핸들러(Storage Engine)는 손과 발에 비유될 수 있다.
- 실행 엔진은 핸들러에게 임시 테이블을 만들라고 요청을 한다.
- 다시 실행 엔진은 where 절에 일치하는 레코드를 읽어오라고 핸들러에게 요청한다.
- 읽어온 레코드들을 1번에서 준비한 임시 테이블로 저장하라고 핸들러에게 요청한다.
- 데이터가 준비된 임시 테이블에서 필요한 방식으로 데이터를 읽어오라고 핸들러에게 요청한다.
- 최종적으로 실행 엔진은 결과를 사용자나 다른 모듈로 넘긴다.
실행 엔진은 만들어진 계획대로 각 핸들러에게 요청해서 받은 결과를 또 다른 핸들러 요청의 입력으로 연결하는 역할을 수행한다.
5. 핸들러(Storage Engine)
핸들러는 MySql 서버의 가장 밑단에서 MySql 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 디스크로부터 읽어오는 역할을 담당한다.
핸들러는 결국 스토리지 엔진이 된다.
복제(Replication)

데이터베이스의 데이터가 점점 대용량화 되어가는 만큼 확장성(Scalability)은 DBMS에서 아주 중요한 요소이다. MySql에서는 확장성을 위해 다양한 기술들을 제공하는데 가장 일반적인 방법이 복제(Replication)이다.
복제는 2대 이상의 MySql 서버가 동일한 데이터를 담도록 실시간 동기화하는 기술이다.

일반적으로 MySql 서버의 복제에서는 마스터는 반드시 1개이며, 슬레이브는 1개 이상으로 구성될 수 있다.
보통은 마스터, 슬레이브 중 하나의 역할만을 수행하지만 때때로 MySql 서버 하나가 마스터이면서 슬레이브 역할까지 수행하도록 설정하는 것도 가능하다.
마스터(Master) : MySql 바이너리 로그가 활성화되면 어떤 MySql 서버든지 마스터가 될 수 있다.
어플리케이션의 입장에서 보면, 마스터 장비는 주로 데이터가 생성 및 변경, 삭제 되는 주체(시작점)이라고 볼 수 있다.
일반적으로 MySql 복제를 구성하는 경우 복제에 참여하는 여러 서버 가운데 변경이 허용되는 서버는 마스터로 한정하는 경우가 많다. 그렇지 않은 경우 복제되는 데이터의 일관성을 보장하기가 어려워진다.
마스터 서버에서 실행되는 DML, DDL 가운데 데이터의 구조나 내용을 변경하는 모든 쿼리 문장은 바이너리 로그(binary log)에 기록된다.
슬레이브 서버에서 변경 내역을 요청하면 마스터 장비는 그 바이너리 로그를 읽어 슬레이브로 넘기게 된다.
마스터 장비의 프로세스 가운데 Binlog dump 라는 스레드가 이 일을 전담하는 스레드이다.
만약 하나의 마스터 서버에 10개의 슬레이브가 연결되어 있다면 "Binlog dump" 스레드는 10개가 표시 될 것이다.
슬레이브(Slave) : 데이터(binary log)를 받아 올 마스터 장비의 정보(IP주소, 포트 정보 및 접속 정보)를 가지고 있는 경우 슬레이브에 해당한다.
마스터나 슬레이브는 단지 역할을 의미할 뿐이지, 별도의 빌드 옵션이나 설치가 필요하지는 않다.
마스터 서버가 바이너리 로그를 가지고 있다면 슬레이브 서버는 릴레이 로그(Relay log)를 가지고 있다.
일반적으로 마스터와 슬레이브의 데이터를 동일한 상태로 유지하기 위해 슬레이브 서버는 읽기전용으로 설정할 때가 많다.
슬레이브 서버의 I/O 스레드는 마스터 서버에 접속해 변경 내역을 요청하고, 받아온 변경 내역을 릴레이 로그에 기록한다.
그 다음 슬레이브 서버의 SQL 스레드가 릴레이 로그에 기록 된 변경 내역을 재실행(Replay)함으로써 슬레이브의 데이터를 마스터와 동일한 상태로 유지한다.
I/O 스레드와 SQL 스레드는 마스터 MySql에서는 기동되지 않으며, 복제가 설정된 슬레이브 MySql 서버에서 자동적으로 기동하는 스레드이다.
하지만 복제를 사용할 경우 주의해야 할 사항이 있다.
1) 슬레이브는 하나의 마스터만 설정 할 수 있다.
하나의 마스터의 N개의 슬레이브는 일반적인 형태이며, 그 밖에 링(Ring) 형태나 트리(Tree)형태의 구성도 가능하다.
또한 많이 사용하지는 않지만, 마스터-마스터 형태의 복제도 가능하다. 2개의 서버가 모두 마스터이면서 슬레이브가 되는 형태이다.
2) 마스터 슬레이브의 데이터 동기화를 위해 슬레이브는 읽기 전용으로 설정한다.
마스터와 슬레이브로 복제가 구성된 상태에서 데이터는 마스터로 접속해서 변경해야 한다.
3) 슬레이브 서버용 장비는 마스터와 동일한 사양이 적합하다.
변경이 매우 잦은 MySql 서버일 수록 마스터 서버의 사양보다 슬레이브 서버의 사양이 더 좋아야 마스터에서 동시에 여러 개의 스레드로 실행된 쿼리가 슬레이브에서 지연되지 않고, 하나의 스레드로 처리될 수 있다.
또한, 슬레이브 서버는 마스터 서버가 다운된 경우 그에 대한 복구 대안으로 사용될 때도 많기 때문에 사양을 동일하게 맞추는 경우가 대부분이다.
4) 복제가 불필요한 경우, 바이너리 로그를 중지한다.
바이너리 로그를 작성하기 위해 MySql은 상당히 많은 자원을 소모하고, 그로인해 성능이 저하된다.
바이너리 로그를 안정적으로 기록하기 위해 Gap lock을 유지하고, 매번 트랜잭션이 커밋될 때마다 데이터를 변경시킨 쿼리 문장을 바이너리 로그에 기록해야 한다.
특정한 경우 바이너리 로그에 정확히 기록되고 나서야 사용자가 요청한 쿼리 문장이 완료될 때도 있다.
바이너리 로그를 기록하는 작업은 특히 AutoCommit이 활성화 된 MySql 서버에서 더 심각한 부하로 나타날 때가 많다. 특히 트랜잭션을 지원하지 않는 MyISAM 테이블은 항상 AutoCommit 모드로 작동하기 때문에 InnoDB 테이블보다 바이너리 로그를 기록하는데 더 많은 자원을 사용하게 된다.
바이너리 로그가 성능에 많은 영향을 미치기 때문에, 고려해야 한다.
5) 바이너리 로그와 트랜잭션 격리 수준(Isolation level)
바이너리 로그 파일은 어떤 내용이 기록되느냐에 따라 Statement 포맷 방식과 Row 포맷 방식이 있다.
Statement 포맷 방식은 바이너리 로그 파일에 마스터에서 실행되는 쿼리 문장을 기록하는 방식이며, Row 포맷 방식은 마스터에서 실행된 쿼리에 의해 변경된 레코드 값을 기록하는 방식이다.
SQL 기반의 복제는 아무리 데이터의 변경을 많이 유발하는 쿼리라 하더라도, SQL 문장 하나만 슬레이브로 전달되므로 네트워크 트래픽을 많이 유발하지는 않는다.
하지만 SQL 기반의 복제가 정상적으로 작동하려면 REPEATABLE-READ 이상의 트랜잭션 격리 수준을 사용해야 하며, 그로 인해 InnoDB 테이블에서는 레코드 간의 간격을 잠그는 Gap lock이나 next key lock 이 필요해진다.
반면 레코드 기반의 복제는 마스터와 슬레이브 MySql 서버 간의 네트워크 트래픽을 많이 발생시킬 수는 있지만 READ-COMMITTED 트랜잭션 격리수준에서도 작동할 수 있어 InnoDB 테이블에서 잠금의 경합은 줄어든다.
더 찾아봐야 할 부분
gap lock, next key lock, InnoDB
참고
'DB > MySql' 카테고리의 다른 글
| [MySql] 쿼리 캐시 (0) | 2019.06.27 |
|---|---|
| [MySql] 실행계획 (0) | 2019.05.04 |
| [MySql] Procedure로 loop insert (0) | 2019.03.21 |


댓글