[MySql] 실행계획
MySql 실행 계획
DBMS의 쿼리가 실행되면 결과를 출력하는 방법은 아주 많이 있지만, 그 중에서 최적화된 방법을 결정해야 한다.
DBMS에서는 쿼리를 최적으로 실행하기 위해 각 테이블의 데이터가 어떤 분포로 저장돼 있는지 통계 정보를 참조하고, 그 기본 데이터를 비교해 최적의 실행 계획을 수립하는 작업이 필요하다.
이런 역할을 하는 것이 DBMS의 옵티마이저다.
모든 DBMS의 옵티마이저는 가장 복잡하고, 이해하기 어렵다.
하지만 실행 계획을 이해할 수 있어야 불합리한 부분을 찾아내, 더욱 최적화된 방법으로 계획을 수립하도록 유도할 수 있다.
쿼리 실행 절차
크게 3가지로 나눌 수 있다.
- 사용자로부터 요청된 SQL 문장을 잘게 쪼개서 MySql 서버가 이해할 수 있는 수준으로 분리
- SQL의 파싱 정보(파스 트리)를 확인하면서 어떤 테이블부터 읽고 어떤 인덱스를 이용해 테이블을 읽을지 선택
- 2번에서 결정된 테이블의 읽기 순서나 선택된 인덱스를 이용해 스토리지 엔진으로부터 데이터를 가져옴
첫 번째 단계를 "Sql 파싱" 이라고 하고, MySql 서버의 "Sql 파서" 라는 모듈로 처리한다.
만약 Sql 문장이 문법적으로 잘못됐다면 이 단계에서 걸러진다.
또한 "Sql 파스 트리"가 만들어진다.
MySql 서버는 Sql 파스 트리를 이용해 쿼리를 실행한다.
두 번째 단계는 첫 번째 단계에서 만들어진 Sql 파스 트리를 참조하면서, 다음 내용을 처리한다.
- 불필요한 조건의 제거 및 복잡한 연산의 단순화
- 여러 테이블의 조인이 있는 경우 어떤 순서로 테이블을 읽을지 결정
- 각 테이블에 사용된 조건과 인덱스 통계 정보를 이용해 사용할 인덱스 결정
- 가져온 레코드들을 임시 테이블에 넣고 다시 한번 가공해야 하는지 결정
대표적으로 위 작업을 하고, 이 단계는 "최적화 및 실행 계획 수립" 단계이며, MySql 서버의 "옵티마이저"에서 처리한다.
또한 두 번째 단계가 완료되면 쿼리의 "실행 계획"이 만들어진다.
세 번째 단계는 수립된 실행 계획대로 스토리지 엔진에 레코드를 읽어오도록 요청하고, MySql 엔진에서는 스토리지 엔진으로부터 받은 레코드를 조인하거나 정렬하는 작업을 수행한다.
1, 2 단계는 MySql 엔진에서 처리하며, 세 번째 단계는 MySql 엔진과 스토리지 엔진이 동시에 참여해 처리한다.
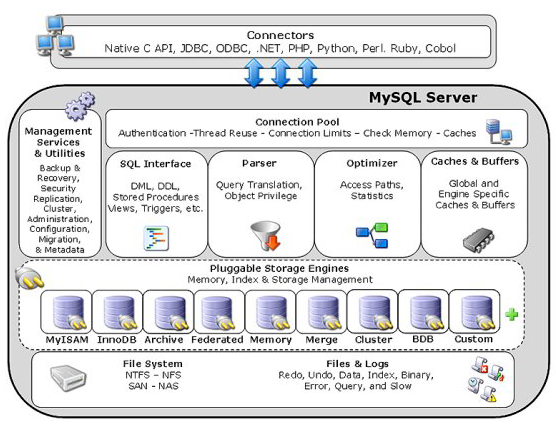
아래 그림은 MySql 의 아키텍처다.
옵티마이저의 종류
옵티마이저는 데이터베이스 서버에 두뇌와 같은 역할을 담당하고 있다.
종류로는 크게 2가지가 있다.
비용 기반 최적화(Cost-based optimizer, CBO)
- 쿼리를 처리하기 위한 여러 가지 방법을 만들고, 각 단위 작업의 비용(부하) 정보와 대상 테이블의 예측된 통계 정보를 이용해 각 실행 계획별 비용을 산출해 최소 비용이 소요되는 방식을 선택한다.
규칙 기반 최적화(Rule-based optimizer, RBO)
- 대상 테이블의 레코드 건수나 선택을 고려하지 않고, 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립한다.
- 하지만 이 방법은 예전에 많이 사용하던 방식이다.
통계 정보
비용 기반 최적화 방법에서 가장 중요한 것이 통계 정보다. 통계 정보가 정확하지 않다면 전혀 엉뚱한 방향으로 쿼리를 실행해 버릴 것이다.
예를 들어 1억 건의 레코드가 저장된 테이블의 통계 정보가 갱신되지 않아 레코드가 10건 미만인 것 처럼 되어 있다면 옵티마이저는 실제 쿼리 실행 시 인덱스 레인지 스캔이 아니라 테이블을 처음부터 끝까지 읽는 방식(풀 테이블 스캔) 으로 실행해 버릴 수 있다.
부정확한 통계 정보로 0.1초짜리 쿼리가 1시간이 걸릴 수 있다.
MySql은 다른 DBMS보다 통계 정보가 다양한 편은 아니라고 한다.
대략의 레코드 건수와 인덱스의 유니크한 값의 개수 정도만 관리된다고 한다 .
대신 MySql에서 통계 정보는 사용자가 알아채지 못하는 순간순간 자동으로 변경되어 상당히 동적인 편이다.
하지만 레코드 건수가 많지 않으면 통계 정보가 상당히 부정확한 경우가 많아 "ANALYZE" 명령으로 강제적으로 통계 정보를 갱신해야 할 때도 있다.
Memory 테이블은 별도로 통계 정보가 없고, MyISAM과 InnoDB의 테이블과 인덱스 통계 정보는 다음과 같이 확인할 수 있다.
ANALYZE 명령은 인덱스 키 값의 분포도만 업데이트하며, 전체 테이블 건수는 테이블의 전체 페이지 수를 이용해 예측한다.
show table status like '테이블명'; // 해당 테이블의 상세정보
show index from '테이블명' //인덱스 보기
analyze table '테이블명' //파티션을 사용하지 않는 일반 테이블의 통계 정보 수집
alter table '테이블명' analyze partition p3; // 파티션을 사용하는 테이블의 특정 파티션 통계 정보 수집
analyze를 실행하는 동안 MyISAM 테이블은 읽기는 가능하지만 쓰기는 되지 않는다.
하지만 InnoDB 테이블은 읽기와 쓰기 모두 불가능하므로 서비스 도중에는 analyze를 실행하지 않는 것이 좋다.
MyISAM 테이블의 analyze는 정확한 키값 분포도를 위해 인덱스 전체를 스캔하므로 많은 시간이 소요된다.
반면에 InnoDB 테이블은 인덱스 페이지 중에서 8개 정도만 랜덤하게 선택해서 분석하고 그 결과를 인덱스의 통계 정보로 갱신한다.
MySql 5.1.38 이상의 InnoDB 플러그인 버전에서는 분석할 인덱스 페이지의 개수를
"innodb_stats_sample_pages" 파라미터로 지정할 수 있다.
하지만 기본값 8개에서 2~3배 이상을 벗어나지 않도록 설정하는게 좋다고 한다.
실행 계획 분석
MySql 에서 쿼리의 실행계획을 확인하려면 EXPLAIN 명령을 사용하자.
아무런 옵션 없이 명령을 사용하면 기본적인 쿼리 실행 계획만 보인다.
EXPLAIN EXTENDED나 EXPLAIN PARTITIONS 명령을 이용하면 더 상세한 실행계획을 확인할 수도 있다.
하지만 MySql에서는 Update, Insert, Delete 문장에 대해 실행 계획을 확인할 방법이 없다.
확인하려면 Where 조건절만 같은 select 문장을 만들어 대략적으로 확인해봐야 한다.
사용방법은 옵션이 없는경우 explain 키워드 뒤에 확인하고 싶은 select 쿼리문장을 작성하면 된다.
explain
select * from batch_step_execution;
출력된 결과에서 위쪽에 출력된 결과일 수록(id 칼럼의 숫자가 작을수록) 쿼리의 바깥(outer) 부분이거나 먼저 접근한 테이블이고, 아래쪽에 출력된 결과일수록(id 칼럼의 숫자가 클수록 ) 쿼리의 안쪽(inner) 부분 또는 나중에 접근한 테이블에 해당된다.
EXPLAIN EXTENDED(Filtered 칼럼)
MySql 5.1.12 버전부터 필터링이 얼마나 효율적으로 실행됐는지 알려주기 위해 Filtered 칼럼이 추가되었다.
EXPLAIN extended
select * from batch_step_execution
where job_execution_id between 10 and 20;이런식으로 작성을 하게되면
필터링된 칼럼의 남아있는 데이터의 비율을 말해준다.
결과값이 20이라면 전체 데이터에서 20%만 남은 것이다.
EXPLAIN PARTITIONS(Partitions 칼럼)
이 옵션으로 파티션 테이블의 실행 계획 정보를 더 자세히 확인할 수 있다.
이 명령을 사용하면 쿼리를 실행하기 위해 파티션 중 어떤 파티션을 사용했는지의 정보를 조회할 수 있다.
우선 내가 이해할 만한 부분은 여기까지 인 것 같다.
나머지는 추후에 더 정리를 해보자.
[참고]