[Kafka] 카프카, 데이터 플랫폼의 최강자 6~10장
6. 카프카 운영 가이드
6.1 카프카 명령어
(우리팀은 대쉬보드로 관리하기 때문에 간단하게만 정리)
kafka-topic.sh // 카프카 생성, 토픽 정보 확인
kafka-config.sh // 카프카 설정 변경
kafka-consumer-groups.sh // 컨슈머 그룹 리스트, 상태와 오프셋 확인운영중인 카프카의 디스크 공간을 확보하는 가장 좋은 방법
- 디스크 공간을 가장 많이 차지하는 토픽의 보관 주기를 줄여주는 것
리플리케이션 팩터 변경시 리더 정보가 변경되면 안됨
LAG이 계속 증가하는 상황
- 컨슈머 처리가 늦어지고있다.
- 컨슈머 or 파티션 수를 늘려서 대응을 해야 한다.
- 특정 파티션에서만 LAG이 증가한다면 해당 파티션에 연결된 컨슈머를 확인 해야 한다.
6.2 주키퍼 스케일 아웃
주키퍼 스케일 아웃시 각 서버에 myid 추가 후, 주키퍼 환경설정 파일인 zoo.cfg 파일에 추가
예를 들어 기존 앙상블이 3대로 구성되어 있고 4,5 번을 추가로 구성한다면, 4,5번에는 앞의 1,2,3번의 설정파일이 추가되어 zoo.cfg에 적용되어있을테지만 기존의 1,2,3에는 4,5번에 대한 설정이 빠져있기 때문에 각각 적용 후 1대씩 재시작 필요함.
systemctl restart zookeeper-server.service // 주키퍼 재시작 명령어
echo mntr // 앙상블 모니터링을 위해 제공하는 명령어
- 팔로워는 보텅 리더를 제외하기 때문에 서버 -1 개로 나옴
- 위 예제에서는 5대로 가정했으니 리더를 제외한 팔로워는 총 4개6.3 카프카 스케일 아웃
- broker.id 만 겹치지 않게 추가하면 끝
추가 후 카프카 실행 systemctl start kafka-server.service- 추가한 서버들이 카프카 클러스터에 조인되었는지 확인 -> 주키퍼 서버에서 broker.id 조회하여 새로 추가한 id 가 잘 조회되는지 확인
- 잘 조회 됐다면, 신규 카프카 서버에 파티션 추가
주의사항
운영중인 카프카의 경우 저장된 파티션의 크기가 크기 때문에 네트워크 사용량 급증 및 브로커에 영향이 갈 수 있기 때문에, 토픽 사용량이 가장 적은 시간에 하는 것을 추천
또는 토픽 보관 주기를 조정해 임시로 사이즈를 축소 시키는 방법
6.4 카프카 모니터링
- JMX를 사용해 설정할 수 있음
- 야후에서 만든 카프카 매니저라는 오픈소스도 있음
- 우리 회사는 카프카 모니터링은 뭐로 하고있지??
6.6 카프카 운영 Q&A
카프카 운영시 옵션을 변경하려면??
- 카프카가 실행되면서 옵션 정보를 읽어오기 때문에, 옵션 변경후 브로커를 1대씩 재시작 해야함
토픽이 삭제되지 않는다??
- delete.topic.enable 옵션이 true로 되어있어야 한다.
디스크 사용량이 높거나 full 이다??
- 카프카 데이터 디렉토리에서 가장 사용량이 많은 토픽을 찾아 보관주기를 변경하여 공간 확보
디스크 추가하는 방법??
- 브로커 옵션 설정에서 log.dirs 옵션에 추가된 디스크 경로를 추가한 후 브로커 재시작
OS 점검은 어떻게??
- 클러스터에서 브로커 1대를 제외한 후 OS 점검 진행
카프카 버전 업그레이드는 어떻게??
- 한 대씩 내렸다가 올리는 롤링 업그레이드
- 모든 브로커를 종료한 후 새로운 버전으로 실행하는 방법
롤링 업그레이드는 어떻게 함??
- 브로커 한 대씩 새 버전을 설치한 후 카프카 환경설정 파일인 server.properties에 버전을 추가한 후 재시작
-
inter.broker.protocol.version=현재 카프카 버전 log.message.format.version=현재 카프카 버전
버전 업그레이드시 주의사항??
- 버전이 업그레이드 되면서 기존 버전의 환결설정 값이 변경되는 경우가 있으니 체크해야함
- 버전의 호환성 체크
카프카 버전 업그레이드시 주키퍼도 업그레이드??
- 별도의 어플리케이션이므로 괜찮다
보통의 자바 기반의 경우 heap 사이즈는 물리 메모리의 절반 정도로 잡는데, 카프카는??
- 힙 사이즈는 5~6GB만 설정하고 남아 있는 메모리는 페이지 캐시로 사용하기를 권장
7. 카프카를 활용한 데이터 파이프라인 구축
나이파이 : 아파치 오픈소스로 데이터 흐름을 정의하고, 정의한 흐름대로 자동으로 실행해주는 어플리케이션 (컨슈머 역할)
파일비트 : 엘라스틱에서 제공하는 경량 데이터 수집기 (프로듀서 역할)
- 나이파이로 가져온 메세지를 엘라스틱서치에 저장해 실시간 분석
- 키바나를 사용해 엘라스틱서치에 저장된 데이터 확인
8. 카프카 스트림즈 API
8.1.1 스트림 프로세싱과 배치 프로세싱
스트림 프로세싱 == 실시간 분석
- 데이터가 분석 시스템이나 프로그램에 도달하자마자 처리됨
- 이벤트에 즉각적으로 반응
- 이벤트 발생 > 분석 > 조치 과정에서 지연시간이 거의 없음
- 정적 분석보다 더 많은 데이터 분석 가능
- 시간에 따라 지속적 유입되는 데이터 분석에 최적화
- 대규모 공유 DB에 대한 요구를 줄일 수 있어서 인프라 독립적으로 수행 가능
배치처리 == 정적 데이터 처리
- 이미 저장된 데이터를 기반으로 분석이나 질의 수행
- 특정 시간에 처리
오늘날의 데이터 분석 시스템은 두 가지 모두를 갖추어 실시간성과 정확성을 갖춤
8.1.2 상태 기반과 무상태 스트림 처리
상태 기반 처리
- 스트림 처리중 이전 스트림의 처리 결과를 참조해야 하는 경우
- 그렇기 위해 각각의 이벤트를 처리 후 그 결과를 저장할 상태 저장소가 필요
- 스트림 처리 어플리케이션이 저장소를 직접 관리하는 경우 -> 내부 상태 저장소
- 별도의 상태 저장소를 사용 -> 외부 상태 저장소
무상태 스트림 처리
- 이전 스트림의 처리 결과와 상관없이 현재 어플리케이션에 도달한 스트림만 기준으로 처리
8.2 카프카 스트림즈
스트림 처리를 하는 프로세서들이 서로 연결되어 토폴로지를 만들어 처리하는 API
특징
- 카프카에 저장된 데이터를 처리하고 분석하기 위해 개발된 클라이언트 라이브러리
- 경량성
- 카프카에 의존성x
- 이중화된 로컬 상태 저장소 지원
- 카프카 브로커나 클라이언트에 장애가 생겨도 1번만 처리되는것을 보장
- 한 번에 하나의 레코드만 처리
- DSL (Domain Specific Language) 지원 -> map, filter, join, aggregations
- 저수준 프로세싱 API 제공
용어
- 스트림 : 카프카 스트림즈 API를 사용해 생성된 토폴로지, 끊임없이 전달되는 데이터 세트, 키-값 형태로 기록
- 스트림 처리 어플리케이션 : 카프카 스트림 클라이언트를 사용하는 어플리케이션, 하나 이상의 프로세서 토폴로지에서 처리되는 로직을 의미
- 스트림 프로세서 : 프로세서 토폴로지를 이루는 하나의 노드, 노드는 연결된 하나의 입력 스트림으로부터 데이터를 받아서 변환 후 다음 연결된 프로세서에 보냄
- 소스 프로세서 : (최상단)위쪽으로 연결된 프로세서가 없는 프로세서, 하나 이상의 카프카 토픽에 데이터를 읽어 아래로 전달
- 싱크 프로세서 : (최하단)아래쪽으로 연결된 프로세서가 없음, 상위 프로세서로부터 받은 데이터를 카프카로 특정 토픽에 저장
카프카 스트림즈 아키텍처
- 각 스트림 파티션은 카프카 토픽 파티션에 저장된 정렬된 메시지
- 스트림의 데이터 레코드는 카프카 해당 토픽의 메시지 (키+값)
- 데이터 레코드의 키를 통해 다음 스트림(카프카 토픽)으로 전달
9. 카프카 SQL을 이용한 스트리밍 처리
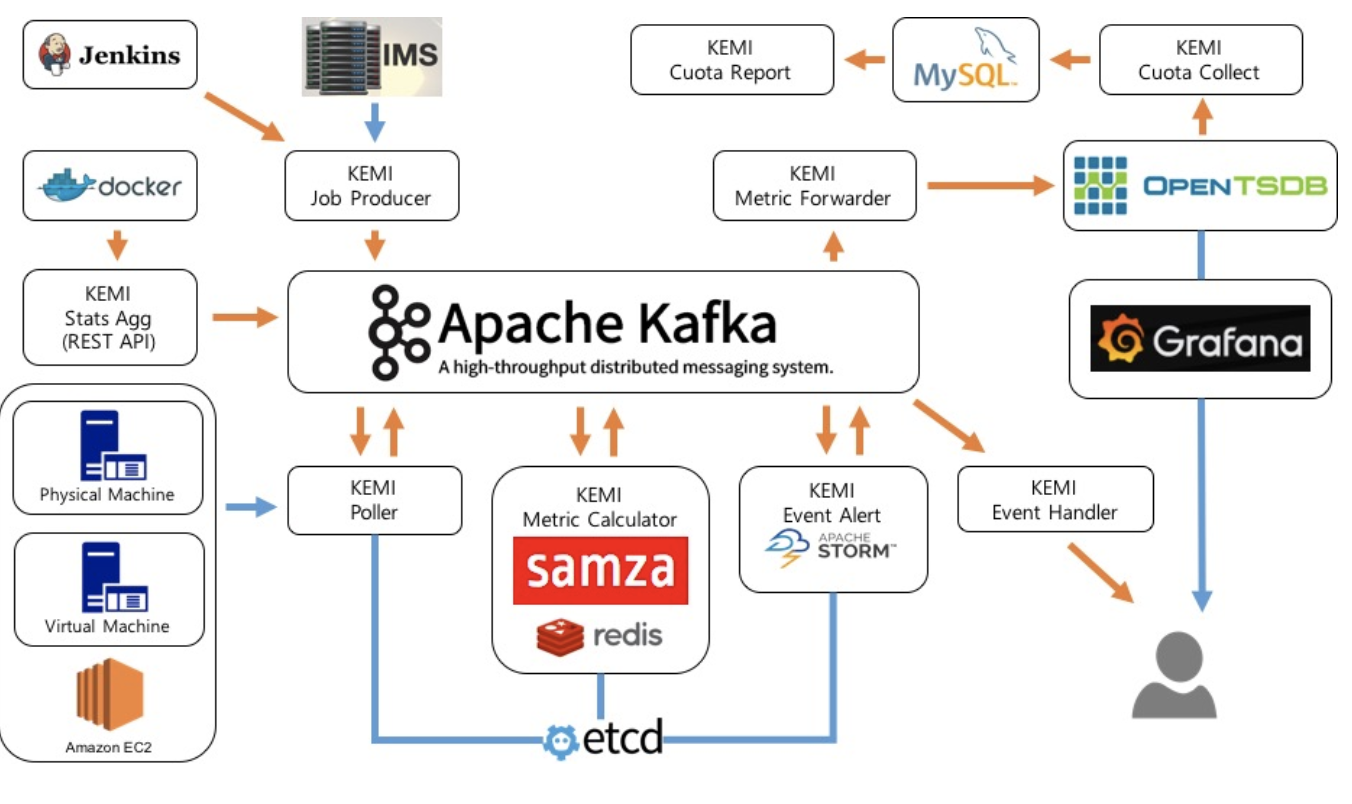
(카카오 KEMI 서비스 아키텍처)
람다 아키텍쳐
- raw 데이터를 처리해 기간과 용량에 따라 별도의 저장소를 가져가는것
- 배치 및 스트림 처리 방법을 모두 활용해 많은 양의 데이터를 처리
- 실시간 분석 지원

장점
- 단기, 장기 데이터를 동시에 관리 가능
- 병목이 생길 경우 특정 컴포넌트만 증가
- 단기/장기 데이터를 어려움 없이 한 번에 조회 가능
단점
- 파이프라인 구성에 많은 기술력 필요
- 단기/장기 데이터를 별도 관리해야하는 부담
위의 단점 때문에 카파 아키텍처가 등장했고 사용하는 기술중 하나가 KSQL , 카프카 SQL
9.2 KSQL과 카파 아키텍처
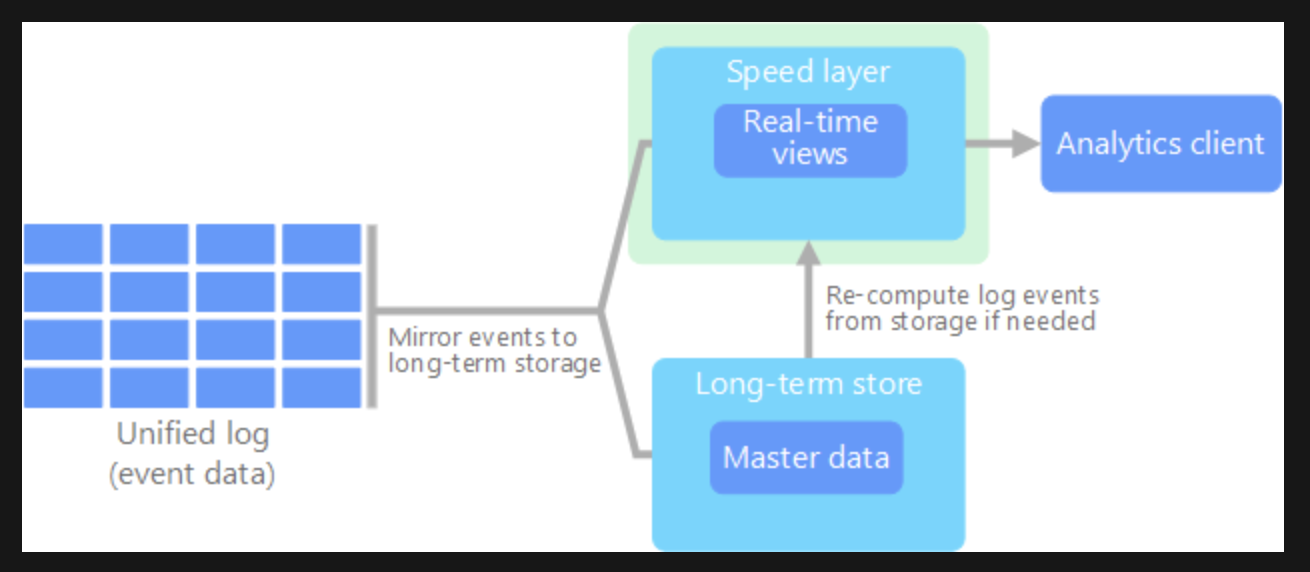
https://docs.microsoft.com/ko-kr/azure/architecture/data-guide/big-data/
람다 아키텍처와의 가장 큰 차이점
- 장기 데이터 조회 필요시 바로 계산해서 결과를 그때 그때 전달 가능
- 장기 데이터를 따로 저장하지 않음
- 장기 데이터는 하둡에 복사해 맵리듀스나 스파크를 통해 결과를 만들어내는 형태
- 단기 데이터는 카프카에 저장
KSQL 아키텍처
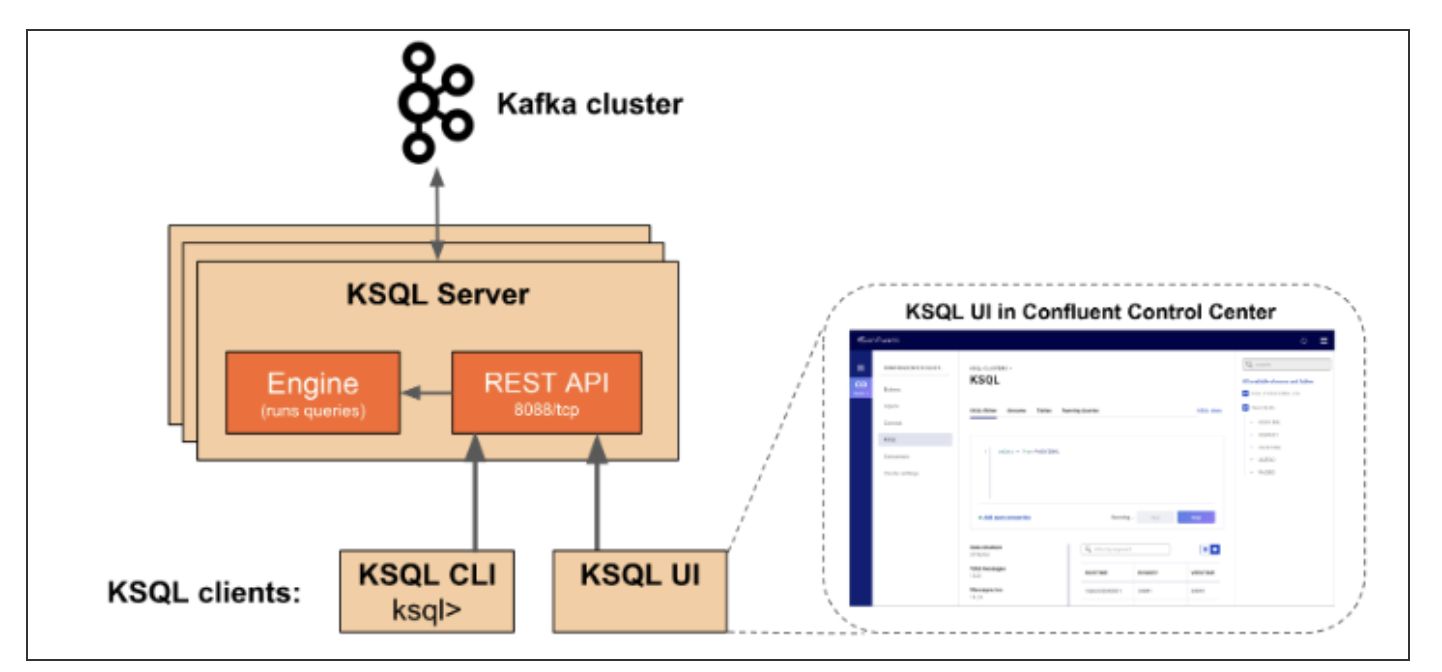
Kafka의 KSQL 컨셉, 아키텍쳐, 용어, 커스텀 function 적용하는 방법
KSQL은 스트리밍 application을 SQL 쿼리를 사용하여 만들 수 있다. KSQL은 Kafka stream으로 만들어져 있다. KSQL은 Kafka 클러스터와 연동되는데 이는 기본적인 Kafka stream application동작구조와 동일하다. K..
blog.voidmainvoid.net
KSQL
- 단기/장기로 저장된 카프카 토픽들을 SQL기반의 쿼리문으로 조회할 수 있게함
KSQL서버
- 사용자로부터 쿼리를 받을 수 있는 REST API 서버와 넘겨 받은 쿼리를 실행하는 KSQL 엔진 클래스로 구성
- 엔진에서 논리/물리적 실행 계획으로 변환하고, 지정된 카프카 클러스터의 토픽으로부터 데이터를 읽거나 토픽을 생성
KSQL 클라이언트
- KSQL에 연결하고 사용자가 SQL 쿼리문을 작성할 수 있게함
9.3.1 KSQL 서버
- 일반적인 DB 쿼리 실행 절차와 동일
쿼리 -> 논리 계획 -> 물리 계획 -> 쿼리 실행 -> 스토리지 저장- 논리/물리 계획을 작성할 때 필요한 메타 정보는 KSQL 서버의 메모리에 저장
- 필요한 경우에는 ksql__commands 라는 카프카 토픽에 저장하는 점이 일반 SQL엔진과의 차이점
ksql__commands 토픽
- KSQL 서버 생성 후 실행한 테이블 관련 명령어가 있음
- KSQL 인스턴스나 서버 추가시 메타 데이터를 클러스터 간 복제하는 것이 아닌 이 토픽을 읽어 자신의 메모리에 생성
9.3.2 KSQL 클라이언트
- DBMS 처럼 SQL을 KSQL서버에 전달하고 결과를 받는 툴
- 마찬가지로 DDL, DML 지원
10. 그 밖의 클라우드 기반 메시징 서비스
- 구글 pub/sub 서비스
- 아마존 키네시스
카프카와의 차이점
- 카프카는 직접 구축, 나머지는 서비스를 받음
- 클라우드 서비스는 리플리케이션 팩터 설정 불가능
- 카프카가 성능에 우위
- 카프카만 데이터 저장기간을 조절 가능
- 클라우드 서비스는 운영 인력이 필요없어서 소규모 회사에서 좋음